
Event narrative ordering by temporal relations
Introduction
Temporal information in sentences are valuable, as that would allow temporal and event-based reasoning in narratives. This kind of information includes not only temporal expression, such as "Friday 13" or "twice a week", but also eventual expressions, such as "fly to Boston" or "teaching computational semantics" because they have a temporal dimension. Treatment of temporal information in natural language can be extended to a larger semantic context, including modality and aspectualilty. Important applications of temporal information extraction and reasoning include the following tasks:
- Temporal query: When did A happen? Is A still hold at current moment?
- Ordering query: Did A happen before B?
This motivates Pustejovsky et. al (2003) to release a Markup Language called TimeML, and later in the same year, a corpus annotated based on that guideline TimeBank. Later development of work on TimeML leads to release of TARSQI toolkit 1.0 (Temporal Awareness and Reasoning Systems for Question Interpretation) by Verhagen et. al (2007). TARSQI employed a pipeline architecture, including syntactic parsing, rule-based extraction of temporal and events expressions, and automatic generation of links (ordering or aspectual) among temporal/event expressions.
A further developement of this discipline leads to three Temp-Eval competitions (part of SemEval competitions), the last one in 2013. In the last instance, there are three subtasks: temporal expression extraction (A), event expression extraction and classification (B), and annotating relations given gold entities (C).
Task description
Training set: SILVER data (2437 out of 2452 documents, 11 are missing because of no syntactical tree). Testing set: TITANIUM data (20 documents). Task: Given correct TIMEX and EVENT (temporal and event expressions), find all temporal relation (TLINK) in the documents and classify them. TLINK can be broken down into 4 types:
- Event-event TLINKs between the main event and all other events in the same sentence (Type 1). Set of labels are AFTER, BEFORE and NORELATION (actually there are more labels in training data set, but I limited training on just three labels)
- Event-event TLINKs between main events in consecutive sentences (Type 2). Set of labels are AFTER, BEFORE and SIMULTANEOUS
- Event-time TLINKS between consecutive event and time in the same sentence (Type 3). Set of labels are IS_INCLUDED, INCLUDES and NORELATION.
- Event-time TLINKS between main event and the document time (Type 4). Set of labels are AFTER, BEFORE and SIMULTANEOUS.
Implementation
Preprocessing
All gold, silver and titanium data are parsed and stored as JSON parsed files by Stanford CoreNLP. Based on the current preprocessing module of tarsqi toolkit, but instead of using the code to tokenize and pos-tag, I directly use the result obtained from the JSON parsed files. Tokenized document with POS will be mixed with TIMEX3 and EVENT tags to create full document (applied for all documents in gold, silver, and test data).
Feature extraction
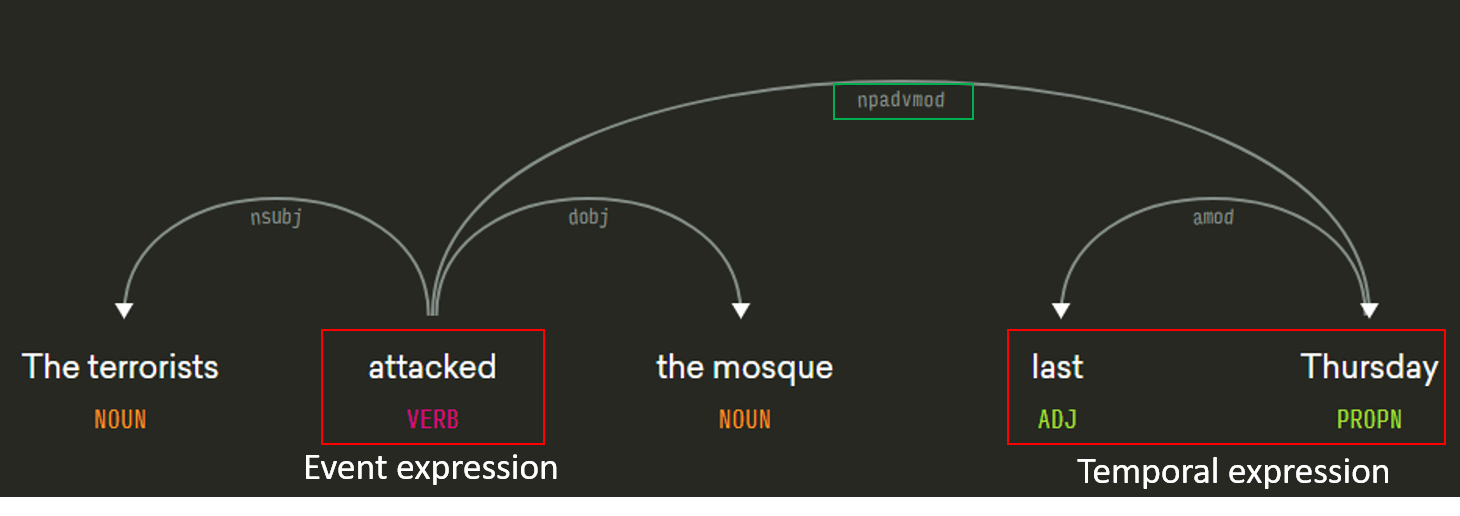
Lemma features for all event and time:- Event: class, aspect, modality, string (all tokens), tense, stem (verb or nouns tokens are stemmed).
- Time: string, type, mode, temporal function (already provided in tarsqi)
Moreover, tree features are extracted using syntactic tree: tree between two events or an event and a temporal expression in the same sentence - a subtree of the syntactical tree parsed by Stanford parser, including the path between the lowest common ancestor (LCA) node and two entity nodes. In addition, I also includes the first level of children of the ancestor node, which include some important information, such as comma , and quote ”. I don’t include the leaves of the tree (lemma and POS)). One more feature is the distance in number of tokens and the distance in number of nodes in the syntactical tree between two events.
Learning algorithm
Support Vector Machine (SVM) is a simple and effective classifier for many tasks. I used a one-to-one version of SVM for each type of TLINK (3 SVM classifiers for each type). Label with most number of votes is selected.
Tree Kernel SVM is a type of SVM that has been used extensively in the NLP literature (Moschitti 2006). Advantages of using Tree Kernel SVM is that ones can employ Tree Kernel, a function that calculate similarity between two tree tructures.
Narrative ordering supplementary data
At the time of I was working on this project, there was some interest in a recent resource developed by Chambers et. al (2010), that provided a database on typical narrative ordering between verb pairs (it counts the number of times a verb A preceed a verb B in a narrative chain). We tried to incorporate that information as a prior for event-event relation.
- 𝑃(𝑙𝑎𝑏𝑒𝑙) is the probability of label in the training data.
- 𝑃(𝑟𝑒𝑠𝑢𝑙𝑡_𝑣𝑒𝑐𝑡𝑜𝑟 | 𝑙𝑎𝑏𝑒𝑙) is the probability of seeing the result vector obtained from SVM_machine given the label. Note that this probablity is not real probablity, but reestimated using the method in Drish (2001), which is a binning method (sorting the training examples according to their scores, and then dividing them into b equal sized sets, or bins, each having an upper and lower bound. Given a test example x, it is placed in a bin according to its score). I implemented this method in Python (because I don't use SVM from scikit-learn, so I have an implementation of my own).
- 𝑃(𝑙𝑒𝑚𝑚𝑎_𝑝𝑎𝑖𝑟 | 𝑎𝑏𝑒𝑙) is calculated from narrative ordering database
Evaluation
Evaluation is taken with 10-fold cross-validation method. This is to account for the fact that the size of data is pretty small.
To date, my implementation is still the start-of-the-art result for the task. Inclusion of narrative ordering didn't really improve performance of the system much, however.
| Implementation | F1 | Precision | Recall |
|---|---|---|---|
| ClearTK-2 | 36.26 | 37.32 | 35.25 |
| My Tree-Kernel SVM | 41.36 | 39.27 | 43.7 |
| Tree-Kernel SVM augmented with narrative ordering | 42.34 | 41.52 | 43.20 |
References
- Pustejovsky, James, et al. "TimeML: Robust specification of event and temporal expressions in text." New directions in question answering 3 (2003): 28-34.
- Pustejovsky, James, et al. "The timebank corpus." Corpus linguistics. Vol. 2003. 2003.
- Verhagen, Marc, et al. "Automating temporal annotation with TARSQI." Proceedings of the ACL 2005 on Interactive poster and demonstration sessions. Association for Computational Linguistics, 2005.
- TARSQI toolkit 2.x (1.0 in 2007)
- UzZaman, Naushad, et al. "Tempeval-3: Evaluating events, time expressions, and temporal relations." arXiv preprint arXiv:1206.5333 (2012)
- Drish, Joseph. "Obtaining calibrated probability estimates from support vector machines." Technique Report, Department of Computer Science and Engineering, University of California, San Diego, CA (2001).
- Chambers, Nathanael, and Daniel Jurafsky. "A Database of Narrative Schemas." LREC. 2010.
- Alessandro Moschitti, Efficient Convolution Kernels for Dependency and Constituent Syntactic Trees. In Proceedings of the 17th European Conference on Machine Learning, Berlin, Germany, 2006.
Resources
Source code