
Verb semantics analysis through distributed representations
This project aimed to find a better linguistic event representation, which normally associates with syntactic structure of verbs. In this work, I proposed a modified model, called Skipgram Backward-Forward that utilizes thematic ordering of verb arguments to create distributed representation for verbs. This representation is then used to carry out a set of experiments, including analogy test, word disambiguation and antonyms-synonyms separation. This page would provide a summary of this project. Please refer to my paper to see more details.
Introduction
Word sense disambiguation (WSD) and word sense induction (WSI) have been the focus of research in Natural Language Processing for several years. To this end, there have been many efforts to create a framework for sense inventory creation and sense-annotated corpora. Among the most notable recent approaches is Corpus Pattern Analysis CPA (Hanks and Pustejovsky, 2005).
Distributional semantic models (DSMs), based upon the assumption that words appearing in similar contexts are semantically related have proven to be a robust and inexpensive approach for a number of applications. Most successful is distributed method - such as Skip-gram (SG) model, proposed by Mikolov et al. (2013b).
Motivated by the fact that the distribution of words before and after a verb typically correspond to its subject and complement collocations, respectively. Therefore, the context distribution before and after the verb are significantly different. A robust system applied for verb meaning needs to leverage this difference to achieve higher performance. Therefore, I proposed a modification version of SG model that takes into account this characteristic.
Implementation
To implement SGBF, I modified the implementation from gensim CPython library. I trained it using a Wikipedia corpus POS-tagged by spaCy library. I only kept the 200,000 most frequent words in the vocabulary. My model learned vectors of 300 dimensions, with the initial learning rate set at 0.025. The maximum context window was set at 4. Following is the skipgram model, in comparsion with my Skipgram Backward forward model:
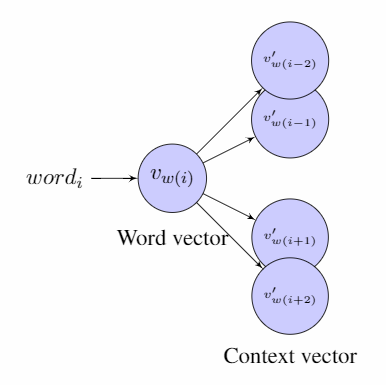
Notice: Learning in the SG-NS-BF model targets matching the left component of the current word vector and the right component of the context word vector, if the context word appears before the current word and vice versa.
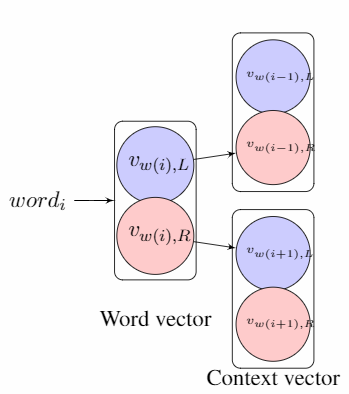
Experiments and results
Analogy test
Analogy test can be stated as following: given that A king to a man is analogous to A queen to a woman, a good vector representation for word should has the following characteristic: vector("King") - vector("Man") + vector("Woman") results in a vector that is closest to the vector representation of the word "Queen".
| Category | SG-NS (Word2Vec) | SG-NS-BF |
|---|---|---|
| gram-7-past-tense | 46% | 54% |
| gram-9-plural-verbs | 61% | 83% |
| antonym-verbs | 11% | 18% |
Word disambiguation in PDEV corpus
Word sense disambiguation has been a focus of researches in NLP. There are two main methods in compiling word senses lexicography resources. One is a top-down approach such as Wordnet, dictating a set of senses for each word lemma; another one is building word senses as patterns of words extracted from a sample size corpus in a bottom-up manner, such as CPA framework
The PDEV corpus is built upon the BNC, using the methodology of Corpus Pattern Analysis (CPA), first outlined in Pustejovsky et al. (2004), and then developed in Hanks and Pustejovsky (2005). Following is a snapshot of patterns for a verb "build":
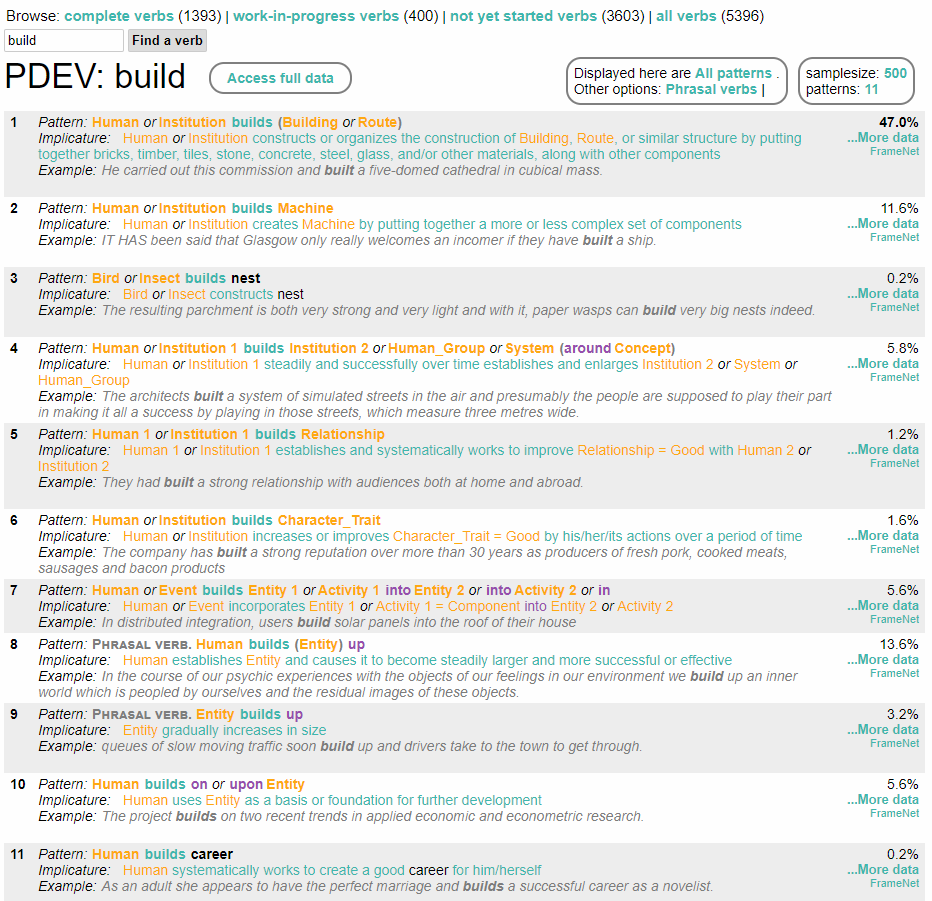
In theory, it is an alternative disambiguation resource for verbs (comparing with other disambiguation resource), such as Babelnet. Its advantage is that verb senses are distinguished through corpus-derived syntagmatic patterns, with inclusion of a number of contextual features, such as minor category parsing, subphrasal cues, and a shallow semantic ontology. However, in practice, it is an underutilized resource.
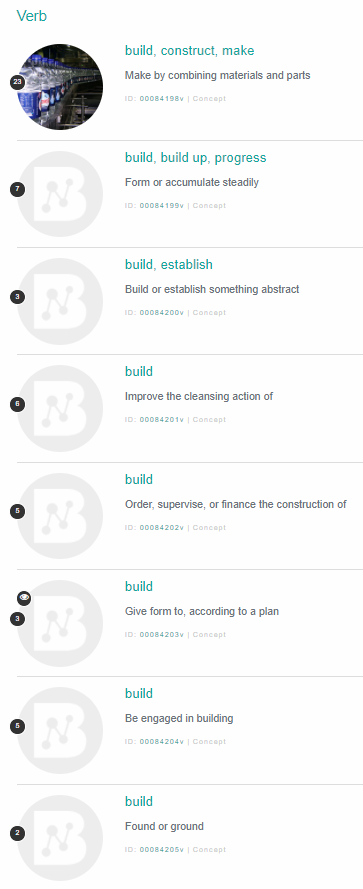
In this subtask, I used the word vector model SG-BF to create prototype vector for each pattern/sense of verbs. It was tested against a two algorithms Bootstrapping and Support vector machien of El Maarouf et al. (2014).
| Bootstrapping method | Support Vector Machine | SG-BF | |
|---|---|---|---|
| Average-Micro | 68% | 82% | 75% |
| Average-Macro | 50% | 52% | 56% |
While SVD method beats our system in MicroAverage metric, SG-BF showed its strength in disambiguating skewed verbs (ones that have dominant pattern), reflecting by higher Macro-Average value.
References
- http://radimrehurek.com/gensim/about.html
- https://honnibal.github.io/spaCy/index.html
- Patrick Hanks and James Pustejovsky. 2005. A pattern dictionary for natural language processing. Revue Francaise de Linguistique Appliquee.
- Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, Jeffrey Dean Distributed Representations of Words and Phrases and their Compositionality In Proceedings of NIPS 2013 El Maarouf, Ismail, et al. "Disambiguating Verbs by Collocation: Corpus Lexicography meets Natural Language Processing." LREC. 2014.
Resources
Distributional Semantics and CPA Pattern Disambiguation